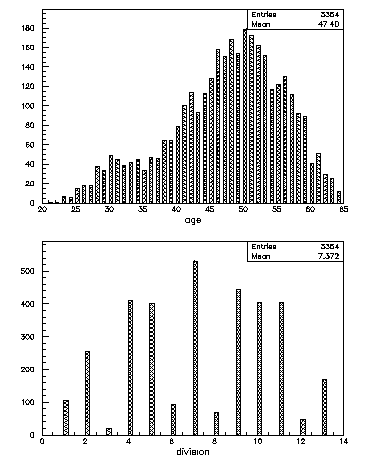
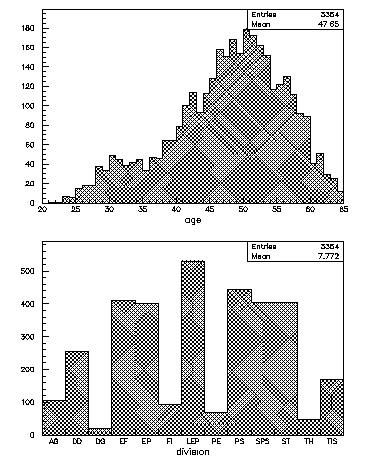
COMIS routine used to create a CW/Ntuple
Subroutine cernpop
*
integer category, flag, age, service, children, grade, step,
+ hrweek, cost
common /cern/ category, flag, age, service, children, grade,
+ step, hrweek, cost
character*4 division, nation
common /cernc/ division, nation
*
character*132 chform
dimension rdata(11)
character*4 divs(13), nats(15)
data divs /'AG', 'DD', 'DG', 'EF', 'EP', 'FI', 'LEP', 'PE',
+ 'PS', 'SPS', 'ST', 'TH', 'TIS'/
data nats /'AT', 'BE', 'CH', 'DE', 'DK', 'ES', 'FR', 'GB',
+ 'GR', 'IT', 'NL', 'NO', 'PT', 'SE', 'ZZ'/
*
open(unit=41,file='aptuple.dat',status='old')
*
call hbnt(11,'CERN Population (CWN)',' ')
chform = ' CATEGORY[100,600]:I, FLAG:U:6, AGE[1,100]:I,'//
+ ' SERVICE[0,60]:I, CHILDREN[0,10]:I, GRADE[3,14]:I,'//
+ ' STEP[0,15]:I, HRWEEK:I, COST:I'
call hbname(11, 'CERN', category, chform)
chform = 'DIVISION:C, NATION:C'
call hbnamc(11, 'CERN', division, chform)
*
10 read(41, '(10F4.0, F7.0)', end=20) rdata
category = rdata(1)
division = divs(int(rdata(2)))
flag = rdata(3)
age = rdata(4)
service = rdata(5)
children = rdata(6)
grade = rdata(7)
step = rdata(8)
nation = nats(int(rdata(9)))
hrweek = rdata(10)
cost = rdata(11)
call hfnt(11)
goto 10
*
20 close (41)
end
|